 VDocRAG
VDocRAG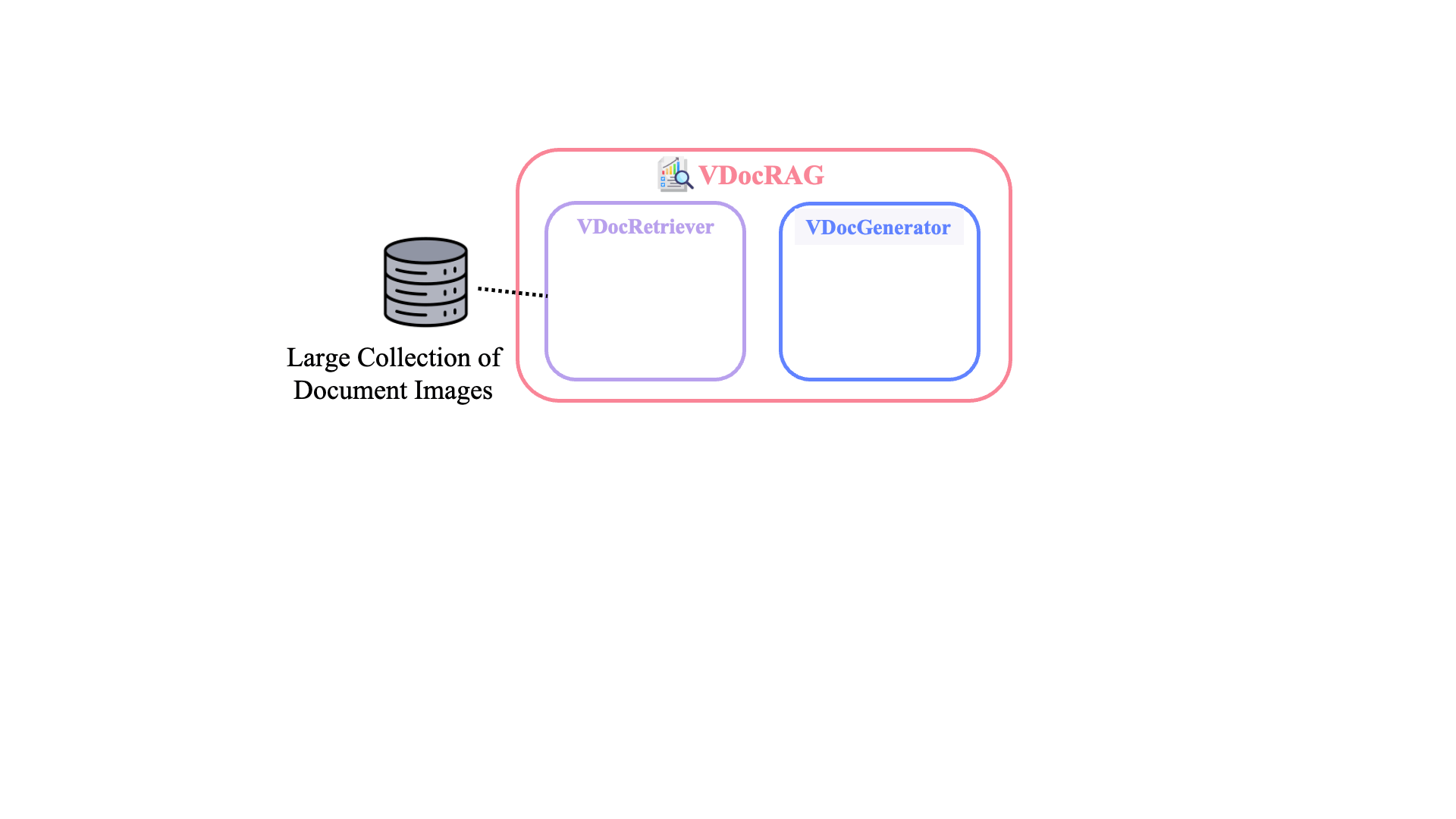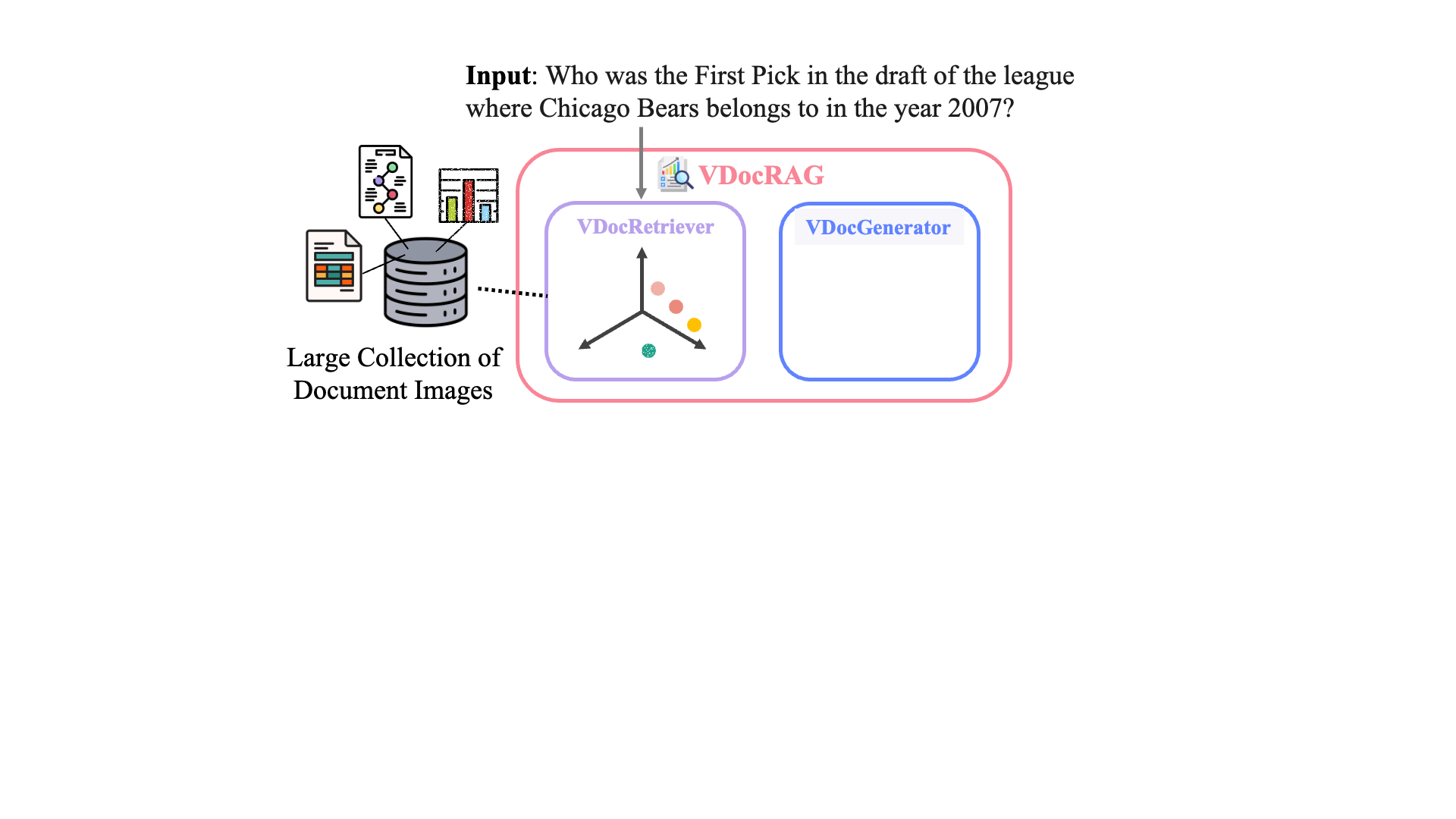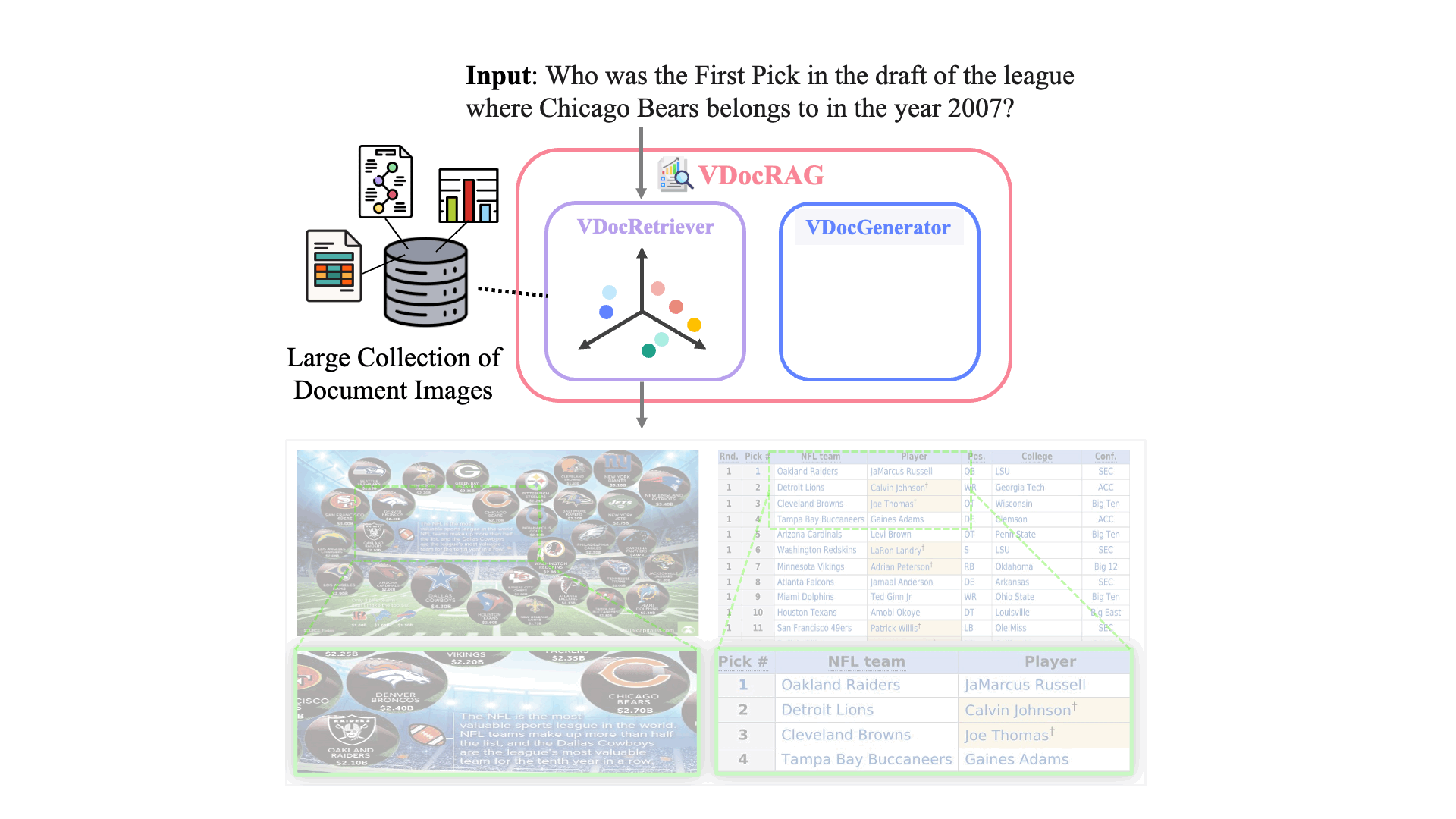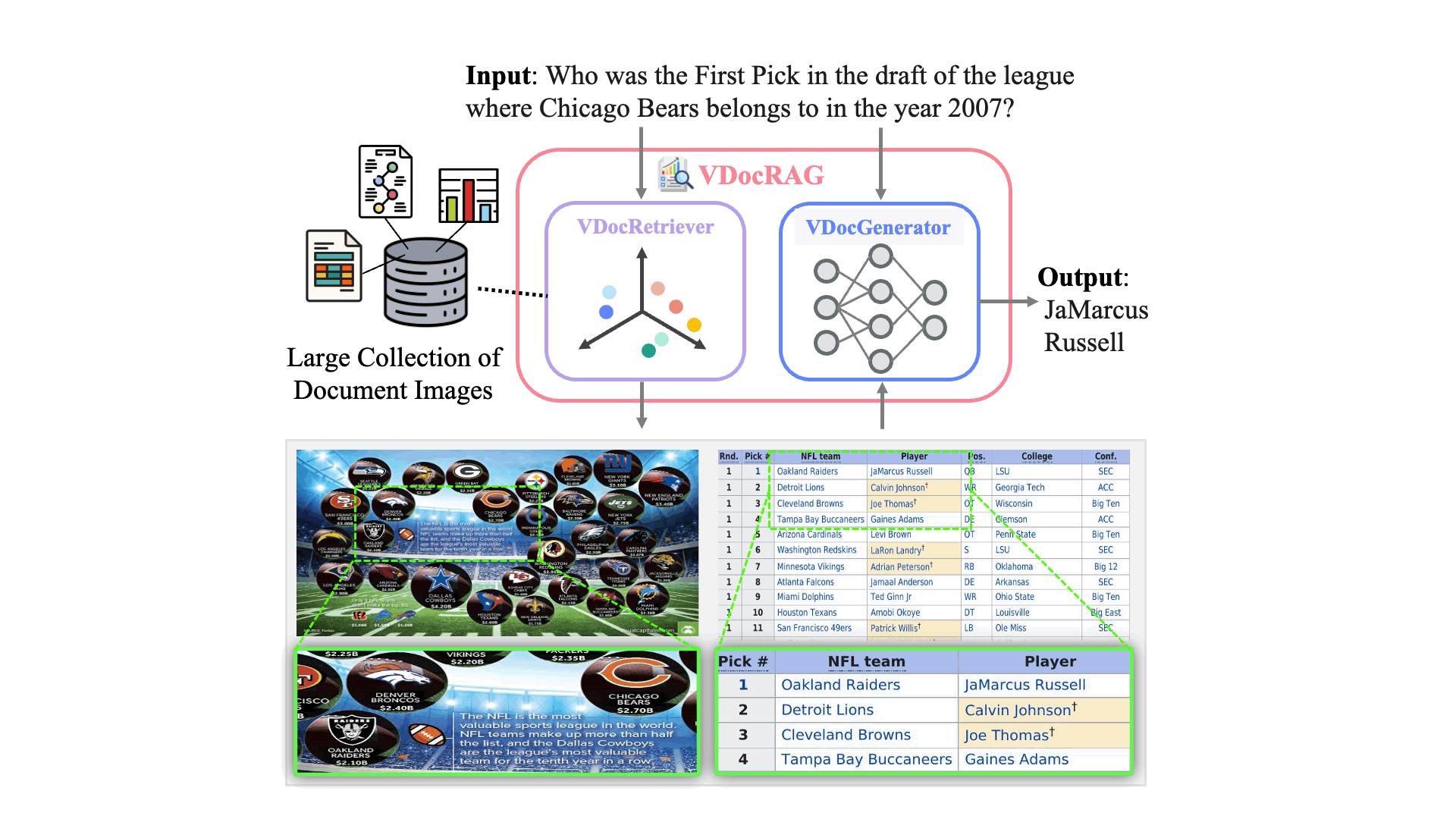 VDocRAG: Retrieval-Augmented Generation over Visually-Rich Documents
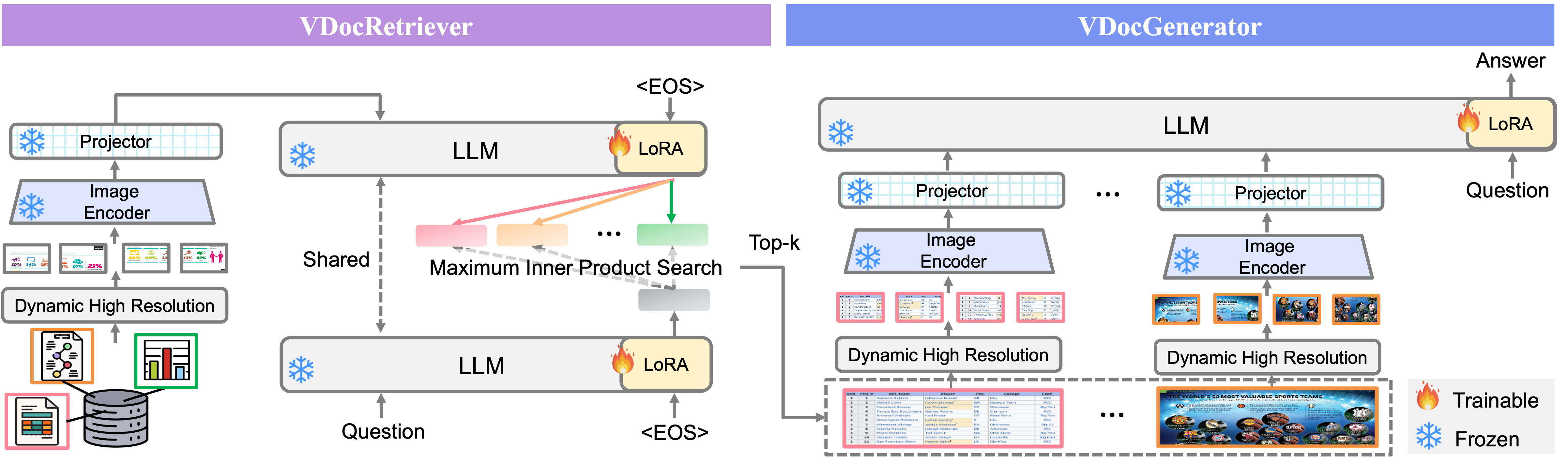
VDocRAG: Retrieval-Augmented Generation over Visually-Rich DocumentsVDocRAG consists of two main components, both of which effectively leverage the visual features of documents.
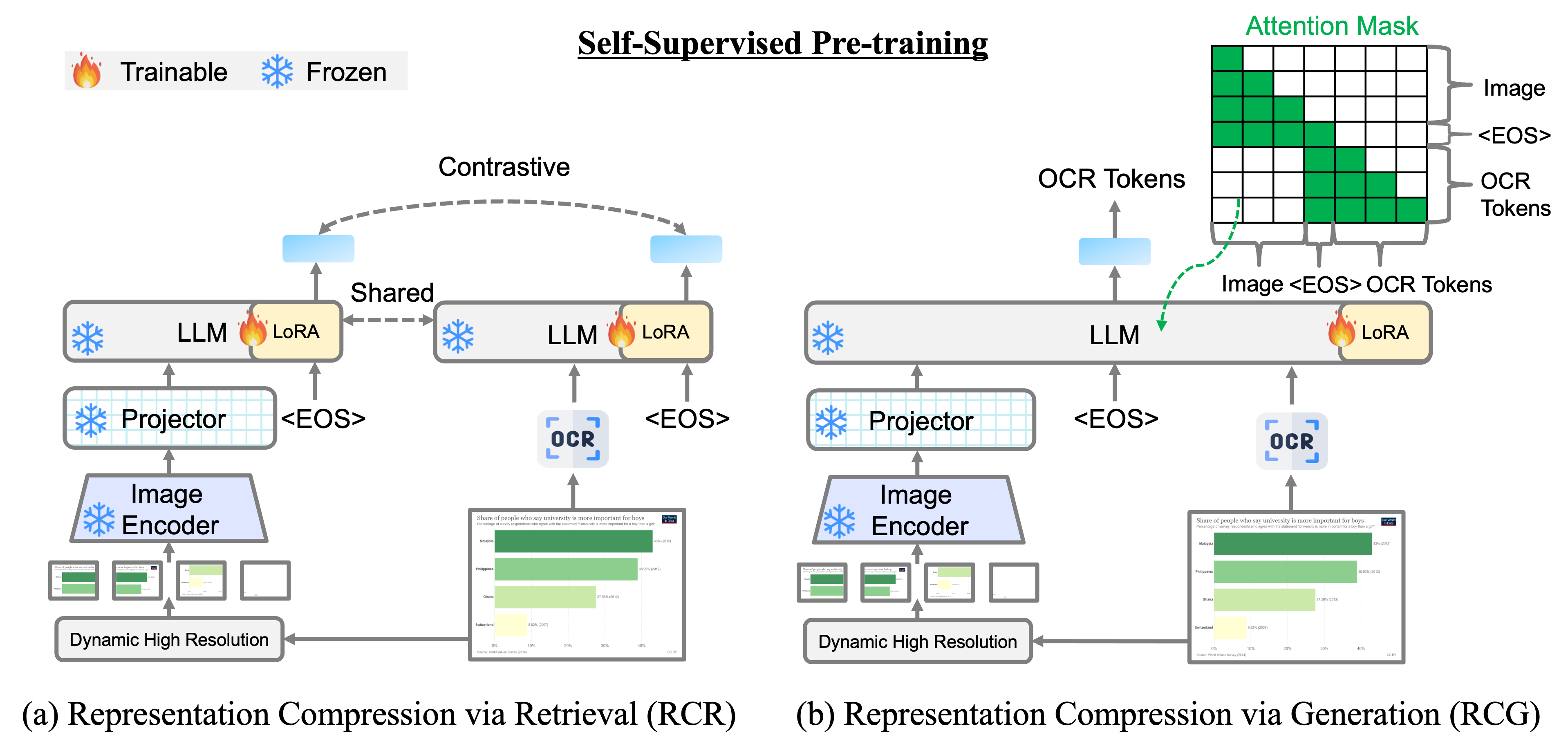
The goal of pre-training is to transfer the powerful understanding and generation abilities of LVLMs to facilitate their usage in visual document retrieval. To this end, we propose two new self-supervised pretraining tasks to compress the entire image representation into the EOS token at the end of the input image. Our pre-training process passes the document image, and its extracted OCR text is used as a pseudo target. Full pre-training objectives is defined as the sum of losses as follows.
Aftere pre-training, we first fine-tune the VDocRetriever with the contrastive learning objective using query-document pairs with in-batch negatives. Then, we apply the trained VDocRetriever to search over the corpus to feed the top-k documents into the VDocGenerator. Finally, we train the VDocGenerator using the next-token prediction.
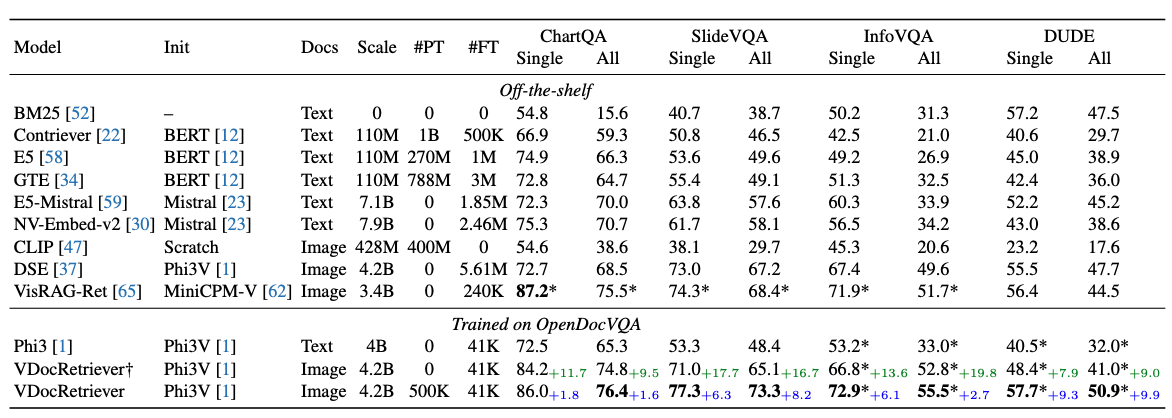
OpenDocVQA is the first unified collection of open-domain DocumentVQA datasets encompassing a wide range of document types and formats, including 43K QA pairs over 200K document images. OpenDocVQA provides a comprehensive resource for training and evaluating retrieval and question answering models on visually-rich documents in an open-domain setting.

VDocRetriever exhibits superior zero-shot generalization on unseen datasets, ChartQA and SlideVQA, outperforming both off-the-shelf text retrievers and the state-of-the-art visual document retrieval models.
VDocRAG significantly outperformed both the closed-book LLM and the text-based RAG on the DocumentVQA task, even when all models were the same initialization.
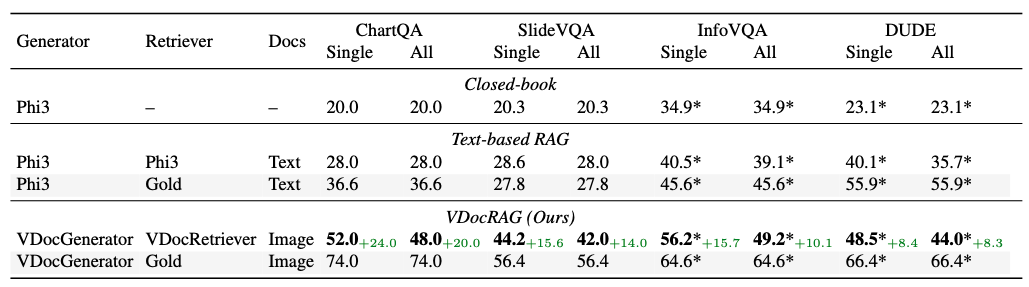
VDocRAG demonstrates significant performance advantages in understanding layouts and visual content, such as tables, charts, figures, and diagrams. These findings highlight the critical role of representing documents as images to improve the performance of the RAG framework.

@inproceedings{tanaka2025vdocrag,
author = {Ryota Tanaka and Taichi Iki and Taku Hasegawa and Kyosuke Nishida and Kuniko Saito and Jun Suzuki},
title = {VDocRAG: Retrieval-Augmented Generation over Visually-Rich Documents},
booktitle = {CVPR},
year = {2025}
}
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.